

随着大数据应用的日益广泛,数据分析在人力资源管理领域中的扮演的角色也越加重要。以往我们都知道数据分析能够帮助企业在人才招聘上提高效率和准确性,但是企业如何去实践落地,外界透露出来的资料和信息都是少之又少。美国Opower公司的这个案例或许能够弥补这方面的不足,让我们能够管中窥豹,看看企业是如何将数据分析应用于人才招聘。

Opower公司简介
Opower公司于2007年成立于美国弗吉尼亚州阿灵顿县,创始人是两位好友亚历克斯·拉斯基(Alex Laskey)和达恩·耶茨(Dan Yates)。该公司的业务领域主要是通过自己的软件,对公用事业企业的能源数据,以及其他各类第三方数据进行深入分析和挖掘,进而为用户提供一整套适合于其生活方式的节能建议。
目前Opower公司在美国、英国、新加坡、日本都设有办公室,员工人数大约600人左右。实际上Opower按规模只够得上是家小公司,还不能算得上是家名企。但是,在2016年,鼎鼎大名的甲骨文用5.32亿美元收购了Opower公司,Opower转身成为了Oracle旗下的一家子公司,从此攀上枝头变凤凰。
Opower的招聘团队
整个公司的招聘团队由15人所组成,每年Opower公司招聘的人数在200人左右,虽然公司小预算有限,但是Opower还是非常重视数据分析在人力资源及招聘活动中发挥的作用,为团队配备了一名全职工程师,专门负责数据分析工作。
Opower的实践之路
1、首次尝试的挫折
Opower公司本身业务的强项就在于使用软件对数据进行分析,因此将自己的专业用在人力资源招聘上也是顺其自然的事情。但是正应了那句中国俗语“隔行如隔山”,Opower公司在能源数据分析上能够得心应手,在人力资源上可未必能够如愿。
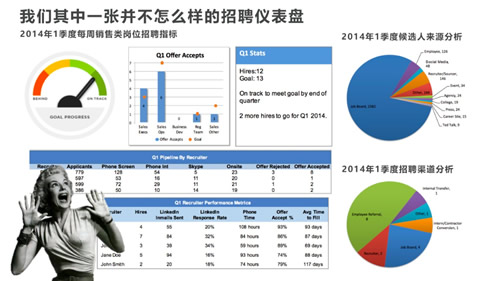
2014年,Opower公司刚刚开始对人才分析领域进行投资,使用“数据仪表盘”为人力资源部门提供例行的招聘数据分析。从到岗时间、电话沟通时间,到人才筛选各阶段的转化指标,数据分析涵盖了招聘指标所涉及的方方面面。起初,仪表盘广受欢迎,设计非常精美,看上去高大上。但很快,在几个月之后,团队意识到仪表盘的作用仅仅是“作秀”。这些仪表盘上的数据并不能为团队带来任何的洞察力,而且更为要命的是数据的准确性出现了很大的问题,因为招聘人员在使用系统的方法并不一致。
另外一个问题就是:团队在整理出这些数据之后,却并不能描述出数据背后所反映的实际问题,因此招聘经理拿到这些数据之后,只能很懵逼的说道:OK,我知道了,可接下来又如何?
2、2015年的转折
经过了2014年的失败,Opower的招聘团队通过实践、反馈,接受内部分析专家的指导得以不断的提升。Opower成为了上市公司,企业发展方向进行了调整,招聘需求也变得更加难以预测。
原来团队中那些精通于某个领域特定角色搜寻的招聘人员,也不得不学习不同领域的业务特点,以满足不断变化的招聘需求。
因此,对于招聘团队业绩的评估就变得越来越来困难。这个时候,整个招聘团队已经到了改变的临界点。
公司接踵而至的变化,导致整个团队的管理方式以及达成目标的方式都需要进行改变,因此招聘团队更换了团队负责人,同时也将之前所使用的数据仪表盘扔近了垃圾堆。
为了能快速进入正轨,整个团队采取了以下措施:
首先,用了一个月的时间来“清洗”我们的历史数据——删除错误数据、编写了一份“清理工作”手册并附以准确的指标;
其次,团队强制性的要求招聘人员使用招聘跟踪系统,并且每周进行工作回顾,为期3个月;
尽管完美的数据是不现实的,但经过3个月的运行,数据已经足够准确。
之后,整个团队停止了每周例行的会议,取而代之的是开展周期性的审查,以确保不出现反复或反弹。
3、开始使用数据解决问题
在完成历史数据的清理工作之后,团队着手解决下一项重大挑战:将数据真正用于解决问题。
在招聘团队中有一个需要回答但是不愿回答的问题:招聘团队需要多少招聘人员,才能满意企业的招聘需求,完成招聘目标。这显然牵涉的就是一个招聘难度的问题,因为企业需要不同岗位的人员,这些不同岗位招聘的难度是不一样的,我们不能仅仅从招聘的数量上来加以说明。但关键点就在于不同岗位的招聘难度如何进行说明解释,它们的难度差异性到底有多大?
Opower的招聘团队开了一个“四象限模型”的框架,通过这个框架可以通过招聘难度而不是招聘数量上来评估招聘人员的工作负荷。
招聘团队综合考量了招聘周期、人才库质量、市场稀缺度以及针对不同岗位的招聘人员负荷,将“四象限模型”的两个维度一个确定为企业对于这个岗位的招聘频率和这个岗位技能的独特性。通过赋予每个象限与招聘难度相关的不同分值,可以计算出招聘人员的分值来衡量他们的工作负荷。如下图所示。

此外,建立在历史数据的基础上,每个象限也都设置了不同的到岗时间要求。
例如,位于第2象限的岗位招聘难度可能相对没有那么大,比如项目经理——这类岗位的技能构成相对常见,而我们也总是在招聘,因此我们招聘的速度也相对较快。
相反,位于第4象限的是我们最为困难的岗位,比如工程副总裁——这类岗位的技能构成非常独特,我们也很少招聘,所以通常需要花费好几个月的时间才能够找到最为合适的候选人。
每个象限的分数代表对应岗位类别所需要付出的努力,这也意味着招聘人员在招聘一位第4象限候选人所付出的努力应当与招聘两位第2象限候选人相当。
在2015年,大多数招聘人员每个季度交付的人员大约在25~30象限得分之间,由于团队会根据岗位的难度进行调整,因而他们的负荷也相对公平。
以下图中的Sally和Bob为例,你们会看到招聘人员绩效指标已经二者之间的比较:
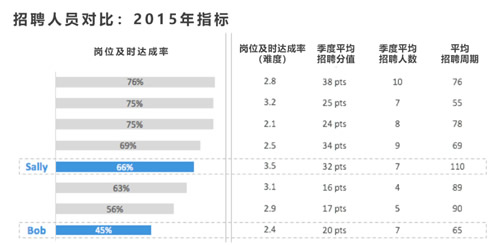
上图显示,尽管在平均到岗时间指标上Sally的表现远不如Bob,她的招聘周期更长,但细分到每个象限的岗位上,她的及时到岗率却更好。
Sally同时也达成了更多的象限得分,相对她所在团队的其他成员,她所负责岗位的招聘难度也更大一些。
此外,如果我们关心Bob的绩效表现,我们可以更为深入地分析其中的原因——
是否候选人被卡在了某个特定的面试环节?
Bob在电话面试时是否进行了有效的资格审核?
Bob候选人的开发是否得力?
通过这种方式,四象限模型成为了我们进一步分类与深挖数据的起点。
更为重要的是,四象限模型帮助我们切实提升了绩效。
在知晓并明确了招聘负荷与目标背后的基本原理之后,我们总能实现既定的工作目标,同时,2015年我们也将平均招聘周期从93天下降到了67天。

4、需求预测与资源获取
在之前的数年中,Opower的招聘预测和多数的企业的做法是一致的:
询问业务负责人当年的招聘需求,结合企业往年离职率评估异动情况,然后,预测搞定。
但不幸的是,这种粗略的预测与实际情况大相径庭,团队也根本无法评估达成招聘目标所需要的资源。
2015年,通过数据与计算,招聘团队已经能够进行更为精确的离职率和增长预测。以下是Opower的招聘团队在2015年进行的一些新的预测实践:
●创建离职率趋势模型,而不再使用平均历史离职率数据;
●在半年度计划中引入了“计划外岗位”分析;
●引入了人员异动率以及进一步的重新需求招聘(因员工离职而重新出现的招聘需求)分析;
●在搜寻过程中取消一定比例的岗位或对岗位描述进行调整
●对招聘人员离开团队的可能性、人员补充及达到标准交付能力周期进行估算(对Opower而言,这一周期大约是4~6个月)
●认识到用人部门经理通常只知道他们当下的招聘需求,而不是半年后的需求。
当招聘团队展示他们对业务带来的招聘需求的预测时,的确遭到了普遍的怀疑。这些预测被认为是“主观合成”的——因为人头的增长相对有限,因此招聘需求应当也是放缓的。对此团队并没有进行反驳,业务部门有他们的预测,而团队有着自己的预测,最后用事实进行对比:
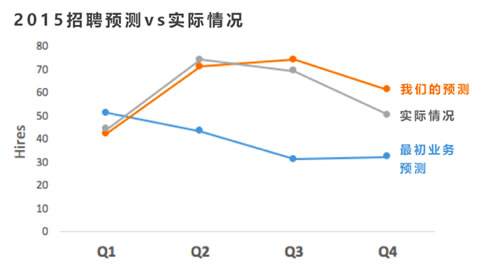
上图显示了在招聘需求的预测方面,团队的预测方法比最初的业务预测更为有效。
对招聘团队而言,这是一次重要的胜利,但接下来的问题就是根据当前的团队情况,实际的交付能力只能满足预计招聘需求的70%,因此团队不得不申请更多的预算。
同时团队向管理层汇报了针对以下3种不同情境的规划:
●与当前已有资源所匹配的能力
●能够立即满足当前招聘需求、但成本相对更高的短期资源需求
●相对经济一些、能够满足85%的招聘目标所需要的长期资源需求
5、起到的效果
整个Opower的招聘团队100%达成了2015年237人的招聘目标
平均每个月通过Hired.com招募到2个招聘难度非常大的技术类候选人
长期资源的投入(合同工、全职雇员)带来了每季度约20人的到岗人员提升
2季度的临时奖励方案有效提升了招聘产出(月度平均到岗时间缩减了4天,每位招聘人员大约额外完成了2个岗位的招聘任务)
6、未能实现的目标
团队的重大失误是针对工程技术人员的10000美元内部推荐奖励完全没有奏效。公司已经有了非常丰厚的内部推荐奖励项目,因此10000美元额外的奖励并没有带来预期的效果,它所增加的只是不合格人选的数量。
7、整合人力资源与招聘数据
2015年团队投入精力所开展的一项重要工作是将招聘数据与其他人力资源数据进行整合,以寻求更为整体与系统的人员战略。来自更多领域的数据能够揭示有关面试有效性、招聘质量、重新需求招聘预测等重要的信息,并产生一些令人力资源总体受益的洞见。
8、面试能够预测绩效表现吗
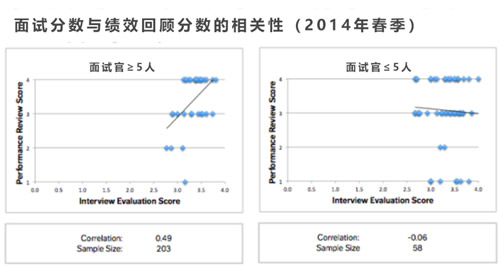
作为关注招聘质量的开始,Opower的招聘团队检验了面试得分是否能够预测员工的绩效表现。
以261位新入职员工为样本,我们将面试得分与绩效回顾的得分进行了比对。
Opower的招聘团队发现,当面试官由5人或更多人组成时,面试得分能够预测绩效表现;然而,如果某项聘用决策是结果少于5人面试而做出的,这一相关性就消失了。
尽管团队都了解相关性应当被谨慎看待,但这一发现对企业的招聘策略产生了重大影响——这是对于团队曾经提出的仅仅依靠几个人(而非整个面试小组)是难以做出有效的聘用决策这一观点的首次验证。
9、招聘质量是否与招聘渠道相关?
绩效评分是衡量招聘质量的一个因素,另一个因素便是员工保留率。
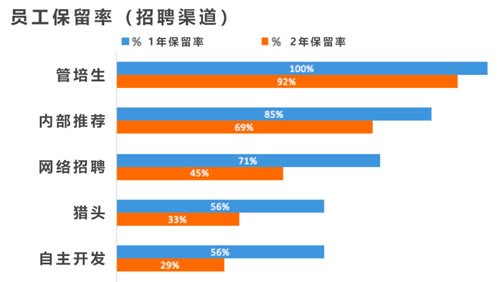
几个月前,招聘团队想了解不同招聘渠道的员工保留率是否存在差异,因此团队就主要的招聘渠道分别分析了1年于2年的员工保留率,数据是这样的:
有趣的是,无论是1年或是2年,管培生与员工内部推荐候选人更倾向于留在Opower,而网络招聘、猎头渠道或被动招聘的保留率则远低于此。
一种假设是内部推荐与管培生在正式加入Opower之前,就能够得到关于实际工作情况最为真实的信息——他们要么已在Opower工作,要么已与他们在这里工作的朋友进行了充分且坦诚的交流。
相反,猎头机构或招聘团队则更倾向于展现企业与团队积极的一面,因而或许未能帮助候选人对企业有客观的了解。
而另一种假设是,内部推荐与管培生更有可能在Opower建立更佳的人际网络。
无论是哪一种原因,招聘团队都能够藉由这一数据,考虑在员工推荐与管培生项目上加大投入,以建立起良好的员工价值主张,并进行一些促进员工保留的尝试。
另外,招聘团队完成了对不同招聘渠道间绩效回顾表现的类似分析,内部推荐、通过网络招聘或招聘人员主动搜寻的候选人,其绩效分布并未显示出明显的差异。
未来,我们还将研究这一趋势是否会持续变化、并评估特定岗位员工的胜任能力,以分析我们的岗位描述与部门经理对特定岗位的要求是否匹配。
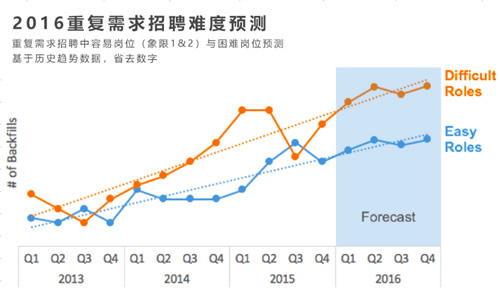
10、基于员工离职的招聘需求预测
四象限模型让招聘团队能够评估因人员离职而带来招聘难度。
首先,历史数据显示有60%的重复需求招聘出现在第3与第4象限,而40%的重复招聘出现在第1象限和第2象限,这意味着在评估需求与资源后进行团队组建时,招聘团队要引入衡量持续增加的重复需求招聘难度的因素;
其次,伴随企业规模的扩大,离职人数的规模也会相应增大,这也将直接影响到企业的招聘计划;
第三,团队将现有员工按照四个象限进行了分类,从而识别与评估不同类别员工的司龄与离职风险。这是团队对此作出的预测:
11、总结
既然企业还需要一些时间继续推动战略的实施,回顾一下Opower的招聘团队所经历的一些失误与遇到的障碍:
①汇报与分析之间的平衡
团队依然会收到关于数据分析或呈现方面的一些额外要求,频繁应对这些要求会牵扯团队进行“真正分析”的精力。
“OK,那团队再聘请几个分析师吧”——说起来容易,但对于有规模限制的团队而言,这样的话毫无意义。
在资源有限的条件下,我们不得不放弃一些无法实现的想法,同时我们也变得更善于考虑优先级。
②工具与系统
目前团队大部分的分析仍然依靠Excel来完成(国外的HR果然还是表哥表姐)。
它很便宜,能够实现我们想要的结果,但是大多数事情仍然需要手工操作。
2016年,我们的主要目标之一是采用像Tableau这样的自动仪表盘工具。
③职责共担
团队的另外一个失误是仅仅让团队中的一位成员负责数据分析。一旦他外出,或有其他的项目工作,就没有人能够临时接替。
需要加强团队内部的培训以拥有后备能力。
④令更多的人了解我们
大多数同事还不了解团队如何在人力资源与招聘中运用人力数据,无论是通过季度的内部邮件、通告栏的公告或是对于重大项目的常见问题,团队都应该在更为广泛的范围内分享他们的研究发现。
⑤人员招聘的要点
以下是一些确保我们的数据分析健康发展的一些“最佳实践”,尽管在很多方面团队做的还不够出色,但我们实践的越多,我们的数据分析能力就会越强。
必做之事:
●设定目标:定义成功,设定可行的、可衡量的目标并实时跟进,能够衡量才有机会改善;
●令你的分析师成为“内部人士”:邀请他们参加战略性会议,他们知道的越多,就能发挥越大的价值;
●讲述故事:你的指标与图表并不会讲话,对要点进行归纳并强调图表上的重点,帮助你的观众更好的理解它们;
●保持好奇:当堆砌在一起的时候,招聘数据毫无帮助,挖掘、归类、识别真正的根源。
●竭力寻求资源:如果你需要资源或专业支持,大胆的求助!向其他部门有分析背景的同事咨询、邀请他们协助你的分析策略;在必要的时候,请求企业的其他分析师批评你的工作。
禁止之事:
●不要令完美成为优秀的敌人:如果你坚持要求完美无缺的数据,你就会误入歧途、错失取得更大成就的机会。不停的询问“与100%准确的数据相比,95%准确的数据会对业务带来怎样的收益?”
●不要轻视快速成效:从你已有的数据着手,复杂与昂贵并不总是好于简单与廉价;
●不要将时间耗费在次要事项上:作为一名数据分析师,你的时间会很容易被那些与你总体战略不符的事情所占用。不必顾忌推掉一些请求;
●不要垂头丧气:分析=延迟的喜悦。期初,你将在基础的工作与问题上投入大量的经历——尽管它们可能并不产生价值,但那只是暂时的;
●不要懈怠:持续迭代,重新评估指标的价值,持续优化你在仪表盘展现的信息,保持全情投入。



