
- 作者 | 刘宇,搜狐集团HRD、22 年人力资源从业经验。
- 来源:内容整理自12月28日《2018全国招聘升级论坛》北京会场,有删减,转载请后台联系。
今天要和大家分享的是关于人才素质模型建模的内容。
首先,我们要澄清做人才建模目的究竟是什么?
这个问题,我跟很多同业交流过,很多人告诉我人才建模的目的是为了在招聘甄选、选拔任用、培训发展的时候用。其实这些不是目的,这些叫应用场景。
在上面这几个场景中,我们使用人才建模的共同目的都是进行人才识别。
我们在进行人才识别的时候,大概有这么几个关注的点:
- 聪明;
- 能干;
- 同心(价值观相符);
- 高潜。
通俗的说,聪明就是智商高;能干就是技能好;同心就是认可团队、企业的文化价值观;高潜就是对未来的预期,能够胜任不断变化的环境下产生的新工作、新任务,有培养和发展的空间。其中,潜力部分的识别尤为困难。
那么做好人才识别的重要因素有哪些?
我个人对事情做得好有个通用的衡量标准,一句话概括就是——意料之外,情理之中。
意料之外就是指创新性,与众不同的做法总是令人赞叹的,是锦上添花的。情理之中是基础,理就是指方法原理,方法论扎实,原理科学。但最容易被忽略的也最重要的是情,情就是用户、客户的接受,主要指能不能和用户、客户同感共情,达成一致。

比如我们跟业务同学沟通某个候选人积极主动、有责任感、专业能力好等等,可业务同学说更看重其创新能力、沟通能力,这就变成了鸡同鸭讲。虽然我们讲的都是对的,但是没有和客户(业务同学)关注点(衡量标准)统一,也就没有共情。
因此,标准的统一和客观性,对形成共识非常重要!
尽管“心理测评”在单一评估工具中不是效率最高的,但是相对其他评估方式其评估方法(同一问卷)与结果输出(标准分)更加客观,更加容易与客户在统一的标准下展开讨论,达成共识。加之其在“潜力”评估方面有不可替代的功效,因而我比较推荐在“人才识别”中应用“心理测评“。
对于人才建模的方式,我们经历过两种。第一种方式我们称之为传统建模,第二种是数据建模。两者在最终应用时都使用“心理测评”工具,但建模的过程不同。
1
传统建模
以领导力建模为例,在传统建模的第一步就是信息输入,我们主要包括文化传承、战略理解、实证分析、标杆研究四个模块。
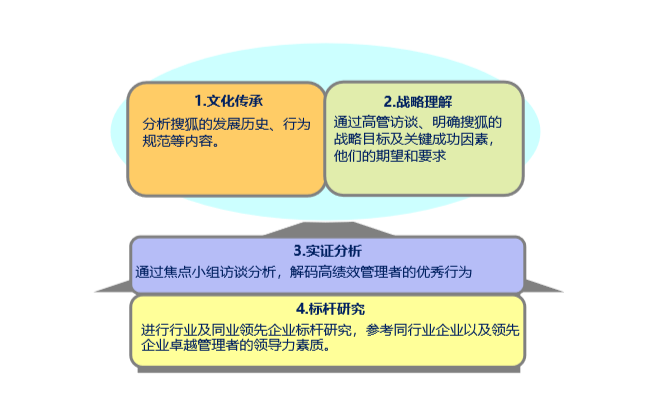
四个模块的信息主要通过文献研究及BEI访谈的方式进行收集,全面从企业的价值观、企业自身以及行业标杆的成功经验、企业未来发展的需求几个方面全面描绘出企业对优秀领导者的能力素质要求。
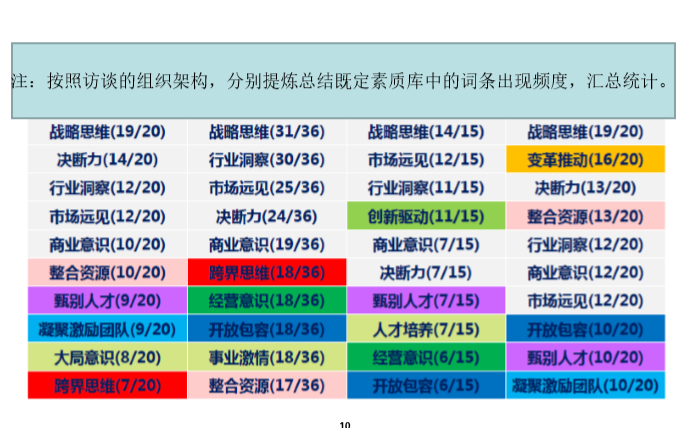
第二步是信息提取,就是要一个描摹词条应用的热点图。
将输入的信息与通用素质库对照、归纳、提炼其中的高频素质词条。基本的呈现方式按照这个图一样,不同的组织架构拆分,分母是访谈对象,分子是词曝光的频度等等。
第三步是逻辑整理。
将高频词进行拆分、压缩、合并,分析梳理内在的逻辑,并用组织惯常使用的理解方式和语言表达出来,便于在组织内部的解读与传播。例如:九项素质可以被梳理成如下的领导力E3模型(Envision、Edge、Engage)。
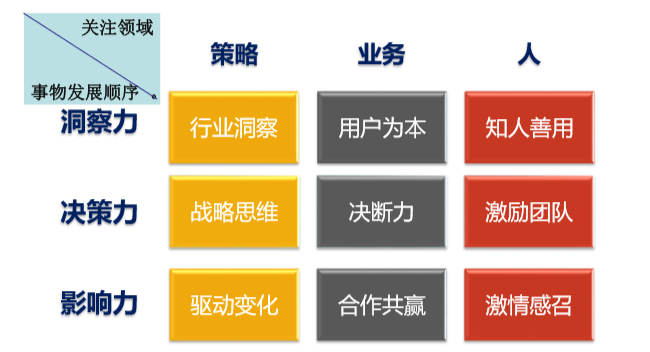
横轴-领导者的工作领域:人、当前业务、未来策略;
纵轴-事情发生、从无到有步骤:察觉了解、做出决策、影响实施。
把建模的素质项目装入这样的九宫格,再重新去看横纵坐标轴交差点的词条,会更好理解和记忆。
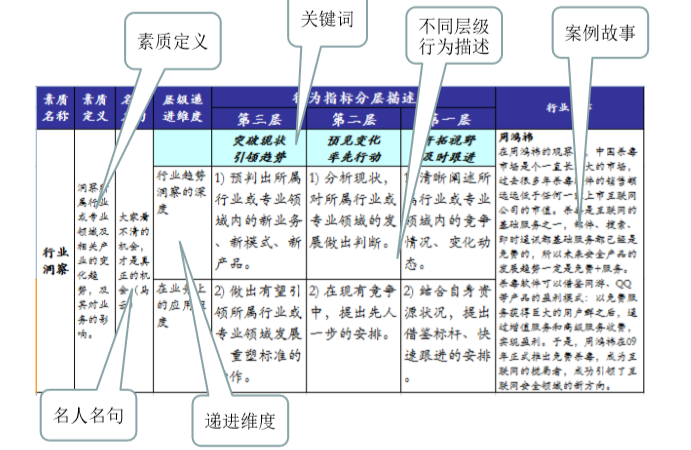
第四步是工具研发。
针对主观的行为评价需求,我们形成一本素质词典,每个词条做相应的行为解读,不同层级还需要设定不同的行为描述,同时辅以素质考察的典型问题,还可以增加一些名言警句或者案例故事,还有考察相关词条的问题库(下图未体现)。
当然,我们也做了基于“心理测评”的评价工具。这一部分的匹配相当困难和不容易完美。我们选择了知名度和美誉度均较高的测评产品,努力学习、理解其中的词条含义,将自己模型的素质词条尽力对应匹配。其中语言翻译的误差、词条语义理解的统一均会对工具的创建造成困难。还有时差的原因,导致这件工作不得不在晚上10点到半夜1、2点的时段进行。这样反复修改了十几稿,持续1个多月才完我们自己的素质模型测评工具开发。
回顾起来,传统建模的优点是:在过程中与管理层及核心绩优人员有充分的沟通,非常有利于在组织内部对领导力模型达成标准的共识;
缺陷是:测评工具对接存在很多困难,并且项目的耗时较长(大概4-5个月),不太顺应企业效率的要求。
2
数据建模
后来我们专业能力建模中更多地采用另外一种建模方式——数据建模,这也是现在很多咨询公司的方式。
首先,直接从数据开始入手先做测评,然后在数据分析中发现素质词条与绩优能力的相关性。

细心的人会发现这种方法只是找到现有、企业内部绩优能力的相关素质?会不会成为“井底之蛙”呢?
我们的方法就是把样本扩展,通过与专业机构合作把行业标杆也纳入到样本库。这样既解决了统计学对样本量的要求(这对单一企业数据建模实践也是现实障碍),也解决扩展了样本的代表性,当然如果还要引入对未来能力需求的素质要求,也可以在所选用的测评工具的素质词条库中进行研究、少量添加。
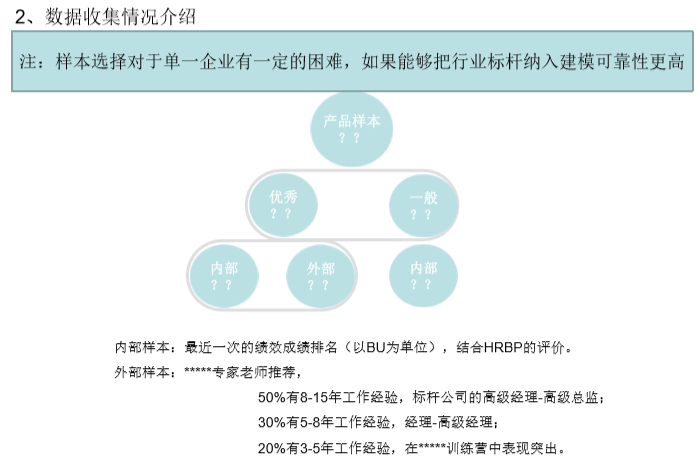
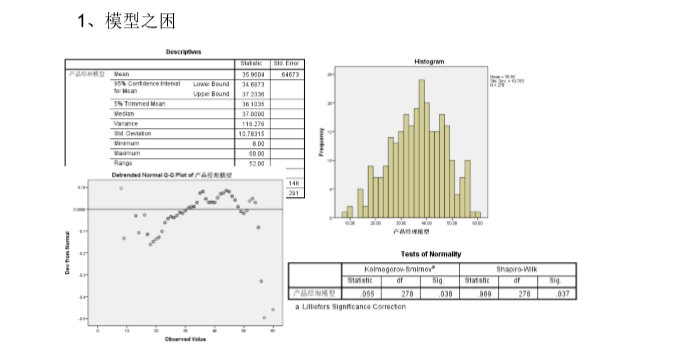
针对样本的测评数据,我们依次进行分布形态、相关性、差异性、均值差异等数据分析工作,最终找到了6条绩优组与各组对比独有的素质项。且6条素质项能够符合常识认知(很容易解释得通)。
这样数据建模获得的模型的好处在哪里?
1、基于数据分析,得出结论的过程更加科学、严谨;
2、数据源于工具,避免再研发工具过程中词条理解转换的误差;
3、建模速度非常快,1-2个月内就可以生成一版模型。
基于这样的数据建模,我们做了若干个模式,有产品、运营、销售以及通用素质模型。大家可以看到,通过对工具已有样本的数据分析,我们可以定位每个模型的效度。

3
建模中遇到的那些坑
我们来看一下,在建模过程中我们遇到的一些坑,希望可以对大家有所帮助。
1、 数据建模是个专业的事情,需要在心理测量方面具备常识且有专业人才。
2、 对于工具的选择,我们需要细心和谨慎的判断。
3、以科学的态度看待测评结果,不轻信、不轻弃。
测评工具基于统计学原理,遵从大数据法则,对于个体不能唯“数值”论,特别是不能在一个分值级别的组里面再进行绝对值排序分高低。
对于测评工具的最佳期待应该是:与业务同学统一评价标准与管理语言,帮助业务同学提示出在日常评估中可能受到晕轮效应影响或容易忽视的视角;
随着数据积累,工具应有不断调优的过程,如果一叶障目就半途而废,是很可惜的。个体案例测评结果和主观认知产生差异时,不能放弃科学性、一票否决,而应该从测评目的与模型适用性,影响相关测评对象能力展现的其他外部因素,以及测评工具中构成相关素质项分值的下一层素质科目的分值及权重情况等进行分析;
期待有更多机会与HR同仁一起探讨建模、测评以及解读的专业知识与实践技能,练就人才识别的“必杀技”!
更多嘉宾分享内容,持续更新中……
