
你可能不知道,2026年仍有超过58%的中小企业在用Excel或微信群管理招聘流程——但与此同时,已导入数据驱动招聘系统的企业,平均招聘周期从47天压缩到了19天,简历筛选效率提升超过80%。这不是技术迭代带来的小优化,而是两种完全不同的招聘认知范式之间的差距。
数据驱动的招聘系统,是指以结构化数据为决策基础,通过系统自动采集、整合、分析招聘全流程数据,实现从渠道投放到人才评估全链路量化管理的招聘管理体系。

招聘数据的价值,99%的HR都低估了
数据驱动招聘系统的核心价值,不在于替代HR,而在于把过去只存在HR脑子里的经验,变成可积累、可复用、可传承的组织资产。
一家快速扩张的零售企业,HR团队6人,每年招聘超过400个岗位。这家公司的招聘总监有一套非常精准的简历判断标准,能在5分钟内判断候选人是否值得推进——但这套标准完全是隐性知识,存在她个人的经验里。当她离职时,这家公司的招聘录用质量在3个月内下滑了30%,新入职的90天离职率从12%跳升到21%。这是一个典型的「人才识别能力无法组织化」的案例,而这个问题本质上是数据问题:判断标准从未被结构化记录,面试评分从未被系统沉淀,渠道质量从未被量化追踪。
根据行业调研数据,企业HR平均每月花费34%的工作时间在数据整理和报告上——但这些手工整理的数据,往往在下一个季度就失效了,因为它们没有跟流程系统打通,更没有在招聘决策中被实际使用。数据有了,但没有被驱动。这才是多数企业招聘管理的真实困境:不是没有数据,而是数据孤立、滞后、无法产生决策价值。
一套完整的数据驱动招聘系统,由哪些部分构成
数据驱动招聘系统的四个核心模块是:渠道效能追踪、候选人数据管道、面试评估量化体系、招聘结果归因分析。这四个模块共同构成一个闭环,让每一次招聘都能产生可学习的数据资产。
渠道效能追踪是起点。不同招聘渠道的简历质量差异极大,但多数企业并不清楚哪个渠道真正带来了优质候选人。以一家500人的科技公司为例,HR团队在BOSS直聘、智联招聘、猎聘三个平台同时投放,每月总费用约6万元。在没有数据追踪的情况下,这笔预算的分配依据是「感觉效果还不错」。引入渠道归因系统后,该团队发现猎聘的简历投递量虽然最低,但进入终面的转化率是BOSS直聘的2.3倍,录用后90天留存率高出17个百分点。基于这组数据,他们将猎聘预算提升了40%,总招聘成本下降了22%,同时提升了入职人员的整体质量。
候选人数据管道是流程层的核心。从简历投递到最终录用,一个候选人要经历6-10个触点:简历筛选、初步沟通、笔试、一面、二面、背调、offer谈判。每个触点都在产生数据,但如果这些数据分散在邮件、微信记录和Excel里,它们就只是噪声。结构化的候选人数据管道,能把每个触点的时间戳、评分、备注自动归集到候选人档案中,形成完整的招聘轨迹。这不只是为了当下的决策,更是为未来的人才激活埋下伏笔——一个当时因薪资未谈拢而未录用的候选人,18个月后可能正好是某个关键岗位的最优人选。
面试评估量化体系解决的是评估标准不一致的问题。同样一个候选人,由不同面试官评估,结论可能截然相反。根据行业研究,非结构化面试的预测效度仅为0.20(满分1.0),也就是说靠感觉面试,结果几乎接近随机。引入结构化评分维度后,预测效度可以提升到0.51,录用精准度提升超过一倍。数据驱动的面试体系,是把「好面试官的评估框架」标准化为系统内的评分卡,让每个面试官的判断都在可比较的坐标上。
招聘结果归因分析是真正拉开差距的模块。多数企业的招聘数据分析止步于「当月录用多少人、岗位达成率多少」——这是结果数据,不是驱动数据。驱动数据是:哪个渠道来的人入职12个月留存率最高?哪类学历背景的候选人在技术岗位表现最好?哪个面试官的推荐录用率最高?当你能回答这些问题,招聘就从运气游戏变成了可优化的科学流程。
没有数据系统,招聘的隐性成本比你想的高得多
很多人以为招聘效率低不过是「慢一点」,但实际上,没有数据支撑的招聘决策,其隐性成本往往是直接成本的3-5倍。
以一个被广泛引用的行业数据为基准:一次中层岗位的错误招聘,综合成本(包括薪资损失、培训投入、团队摩擦、重新招聘费用)平均是该岗位年薪的1.5-2倍。对于一个年薪30万的技术经理,一次错招的成本在45-60万元之间。这个数字,足以支付一套中型企业招聘管理系统3-5年的使用费用。
一家200人规模的制造业企业,在引入数据驱动招聘系统之前,平均招聘周期是52天,90天新员工流失率是19%。HR团队3人,每月用于手工整理简历、协调面试日程、汇总数据报告的时间合计约120小时——相当于每月3个人力周的浪费。引入系统后,招聘周期压缩到24天,90天流失率降至11%,HR团队处理同等招聘量所需时间减少了67%。折算成年化成本,这家企业每年节省的招聘效率损耗和错招成本,约在40-60万元之间。
更深层的代价是组织知识的流失。在没有系统的情况下,每一次招聘都是从零开始的重复劳动:重新定义岗位需求、重新判断渠道、重新校准评估标准。三年的招聘积累,全部存在HR个人的记忆里,一旦人员流动,这些经验就彻底归零。数据系统的价值,本质上是在做组织记忆的基础设施建设。
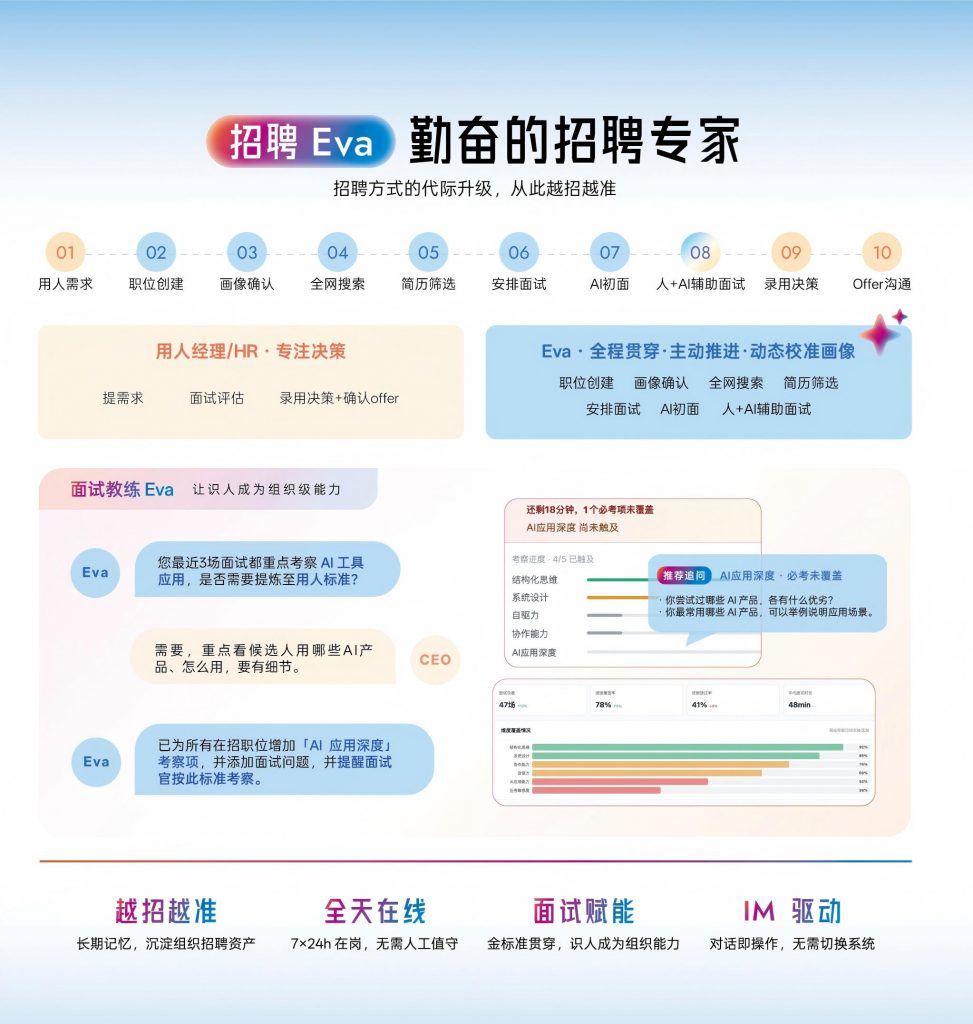
2026年,数据驱动招聘系统长什么样
2026年的数据驱动招聘管理系统,已经不只是一个数据采集和报表工具,而是具备主动分析、预测和推进能力的AI Agent系统。
从功能形态看,当前领先的招聘系统具备以下核心能力:简历结构化解析(从PDF、图片等非结构化格式中准确提取100+字段,准确率超过95%);渠道ROI实时看板(自动汇聚各平台数据,按渠道、岗位类型、部门维度切片分析);候选人画像动态建模(基于历史录用数据,持续学习该企业的人才偏好,越用越准);招聘进度预警(当某个岗位的推进速度低于历史均值时,系统主动提醒并建议备用候选人)。
这里有一个认知盲区值得单独说:多数企业以为数据驱动招聘系统的最大价值是「省时间」,但实际上最大价值是人才库数据资产的复利积累。一个系统持续使用3年,沉淀的候选人档案可能超过10万条,其中20-30%是当时因条件不符而未录用、但能力完全匹配的「准优质人才」。当你再次有招聘需求时,激活这个人才库的成本,不到重新在外部渠道招聘的15%。这才是数据系统真正的长期价值——不是每次招聘省了多少天,而是3年后你拥有了一个比任何同规模竞争对手都更厚实的人才资产。
选一套数据驱动招聘系统,这几个维度不能忽略
能采集数据不等于能驱动决策,这是选型时最容易踩的坑。
数据打通深度是关键。招聘系统采集的数据,如果不能和HRIS(人力资源信息系统)、绩效系统、薪酬系统打通,就无法做招聘结果的长期归因分析——你永远不知道哪个渠道招来的人,在入职2年后绩效最好。真正的数据驱动,需要从招聘延伸到员工全生命周期的数据闭环。
AI能力的深度,而非广度。2026年几乎所有招聘系统都宣称有AI,但差异悬殊。真正有价值的AI能力,是能基于企业自己的历史数据建立个性化模型——而不是给所有客户用同一套通用算法。前者越用越准,后者永远是个平均水平的工具。判断方法很简单:问对方「系统是否支持基于本企业数据的模型微调」,如果答案含糊,大概率是后者。
系统的主动性。传统招聘系统是被动工具:HR去操作,系统记录。新一代AI Agent系统的特征是主动推进:当某个岗位候选人进展停滞,系统会主动提醒;当有新简历匹配某个历史岗位需求,系统会主动推送;当渠道投入产出比异常时,系统会主动预警。主动性,是区分「数据记录工具」和「数据驱动系统」的本质差异。
Moka AI 的招聘 Eva,正是基于这个逻辑构建的。招聘 Eva 具备长期记忆能力,记住每次筛选和面试的反馈,动态更新该企业的人才画像;在候选人进展停滞时主动推进流程;在人才库中自动识别匹配的历史候选人并发起激活。更重要的是,Moka 招聘系统与 Moka People(HCM系统)天然打通,从简历投递到员工入职后的绩效、发展数据,形成完整的数据闭环——让招聘归因分析真正延伸到员工全生命周期。服务3000+企业的过程中,Moka AI积累了跨行业的人才识别经验,同时为每家企业保留独立的个性化模型,实现「通用能力+专属学习」的双轨并行。
想看看 Moka AI 能为你的团队带来多大改变?
Moka AI 为中大型企业提供 AI 原生的招聘管理解决方案,招聘 Eva 作为你最勤奋的 AI 招聘同事,覆盖从简历解析、智能筛选、面试协调到数据归因的全流程,让每一次招聘都在为组织沉淀可复利的人才资产。立即免费试用,用数据验证效果。