
人才画像静态失真,是指企业依据某一时间节点的历史经验构建人才标准,而未能随业务演变、组织变化和市场动态持续更新,导致画像描述与实际用人需求之间产生系统性偏差的现象。这种失真往往是隐性的——招聘在继续,简历在流入,但组织越招越感觉不对劲。
在 2026 年,这个问题比任何时候都更紧迫。当 AI 工具已经重塑了几乎每个岗位的工作方式,当业务方向可能在一个季度内发生根本转变,一份两年前沉淀下来的人才画像,极有可能正在把真正合适的候选人系统性地过滤掉。

一家公司的招聘黑洞:故事从这里开始
2025 年 Q3,徐总作为一家连锁零售企业的 CHO,正在经历她职业生涯中最困惑的一段时间。
公司的数字化转型在这一年全面提速——线下门店开始接入 AI 导购,供应链系统引入了预测性补货模型,总部也上线了实时数据看板。按道理,这是公司需要大量新人的时候。招聘部门确实没闲着,整个 Q3 发出了超过 200 份岗位邀约,其中仅商品运营和供应链方向就开放了 38 个职位。
但到了季度末,正式入职的只有 11 人。漏斗转化率不到 6%。
徐总把这个数字拍在了招聘负责人方经理面前。方经理的第一反应是市场人才不足,但她自己心里也隐约不踏实。她把过去半年被拒的候选人档案翻了一遍,发现了一个细节:有不少候选人曾在新零售或 DTC 品牌做过数据运营,简历上有明确的用户分层和 GMV 运营经验,但系统评分偏低,很多在初筛阶段就被过滤掉了。
原因很简单——公司两年前定下的商品运营画像,核心标准之一是有传统商超或百货背景,并且强调熟悉线下陈列与客情维护。
而他们现在真正缺的,是能看懂用户行为数据、会用 A/B 测试优化货架策略的人。
这两种人,在简历上几乎没有交集。
静态画像是怎么形成的
这不是方经理的失误,也不是哪个人的问题。人才画像静态失真的根源,在于画像本身的生产方式。
大多数企业构建人才画像的方式,本质上是一次性的:HR 与用人部门开一次需求对齐会,结合过去几位优秀员工的背景特征,提炼出一份岗位画像——学历、专业、工作年限、过往公司类型、技能关键词。然后这份画像被写进 JD,录入 ATS 的筛选条件,可能就此运行两三年,期间没有人觉得需要重新审视它。
问题在于:企业在变,岗位在变,但画像没有变。
用人部门觉得招来的人执行力强但缺乏灵活性,HR 觉得候选人背景很好但就是感觉不对,双方都在用直觉判断,却没有人去追问那个底层问题:我们的人才标准,是不是已经过期了?
据行业数据,在业务迭代较快的企业中,超过 70% 的岗位画像存在超过 18 个月未更新的情况。而这些画像沉积的时间越长,筛选出来的人才与实际需求之间的偏差就越大——这就是失真的积累效应。
失真的三种典型形态
回到徐总的故事。她后来和方经理做了一次深度复盘,把过去一年所有的招聘遗憾重新分类。她们发现,静态失真在实际招聘中通常以三种形态出现:
第一种:能力标准滞后。 岗位所需的核心技能已经迁移,但画像仍然强调旧技能。徐总公司的商品运营就是典型——从陈列美感到数据驱动,是一次底层能力的迁移,不是小修小补。
第二种:背景过滤过窄。 画像对过往公司类型有隐性偏好,结果把来自不同行业但具备迁移能力的候选人系统性排除。一个在互联网大厂做过三年精细化运营的候选人,可能比一个在传统百货做了五年的人更适合数字化转型期的商品岗,但他永远过不了第一关。
第三种:文化基因错配。 组织本身在转型,但画像里还留着上一个阶段的理想员工模板。比如,一个从强管控文化转向赋能文化的公司,如果还在按照服从性强、执行稳定来筛人,招进来的人越多,组织转型越难推进。
这三种形态的共同特点是:表面上看像是招聘失败,实际上是标准失真。
为什么 2026 年这个问题被放大了
反常识的结论是:技术进步在某种程度上加剧了静态失真的危害。
逻辑很简单——当 ATS 系统的自动化筛选能力越来越强,把画像转化为筛选规则的效率就越来越高。过去,一个不准确的画像还要经过 HR 的人工判断来兜底。现在,系统在几秒内完成初筛,意味着一个失真的画像可以以极快的速度、极大的规模,把合适的候选人批量过滤出去。
2026 年的另一个变量是 AI 原生岗位的快速涌现。在很多行业,有一批岗位在 18 个月前甚至还不存在,或者刚刚雏形。如果企业还在用 2024 年的认知构建这些岗位的人才画像,几乎注定会出问题。
招聘数据分析层面的数据也在印证这一点。在使用动态招聘数据追踪的企业中,发现岗位画像与实际录用决策之间存在明显背离的比例,在 2026 年已经上升到 43%。换句话说,几乎有一半的岗位,招聘团队实际上是在用直觉推翻系统的筛选结果——这本身就说明画像已经不够准。
方经理的转机
回到故事里。Q3 结束后,方经理做了一个决定:她不打算再等业务部门来更新需求,而是主动发起了一次人才标准重建的项目。
她的做法分三步走:
把过去一年所有通过初筛但最终未录用的候选人档案重新审阅,同时整理所有入职后表现优秀的员工背景——这两组数据对比,往往会暴露出画像失真的具体位置。她发现,表现最好的商品运营人员,有超过 60% 在入职前有过数据产品或电商平台的工作经验,但这一项在原有画像里权重极低。
她和业务方开了一次不一样的需求对齐会。这次她没有问你们需要什么样的人,而是问你们最近半年做了什么决策,用到了什么能力。这个问题视角的转换让讨论质量完全不同——业务方描述的是真实发生的工作场景,而不是抽象的我需要一个有某某背景的人。
把修订后的画像作为假设,而非定论。她在 企业人才库 里重新检索了过去两年被过滤掉的候选人,按照新的标准重新评分,发现其中有 17 人是此前错误过滤的优质候选人,立刻启动了重新激活。
两个月后,这 17 人中有 4 人入职,3 人已经成为业务团队的骨干。
让画像活起来:从静态标准到动态模型
方经理的做法,本质上是在用人工方式做一件事:把静态的人才画像变成动态校准的用人模型。
这件事在 2026 年已经有了系统性的解法。以 Moka AI 招聘管理系统 为例,其招聘 Eva 的核心设计逻辑之一,就是基于企业实际的录用决策和入职后表现数据,持续更新人才画像的权重模型。
具体来说,招聘 Eva 会记录每一次系统推荐但被 HR 否定和系统评分不高但被业务方强烈推荐并录用的案例,从中提取模式——哪些维度在实际决策中被过度加权,哪些维度被系统性低估。这些信号不会等到下次需求对齐会才被整合,而是持续沉淀进模型,形成一个越用越准的动态画像。
这和传统 ATS 的逻辑有根本区别。传统系统是规则引擎——你设定好条件,它按条件筛;招聘 Eva 是学习引擎——它在执行的过程中不断校准,把企业真实的识人偏好变成可积累的组织能力。
这背后的核心价值不是效率,而是认知迁移:把少数有经验的 HR 和业务负责人对好候选人的判断力,变成整个组织可以复用的识人能力。
这也正是方经理在做的事——只不过她用的是手工方式,每次校准要花两三个月。系统化的动态画像,可以把这个周期压缩到实时。
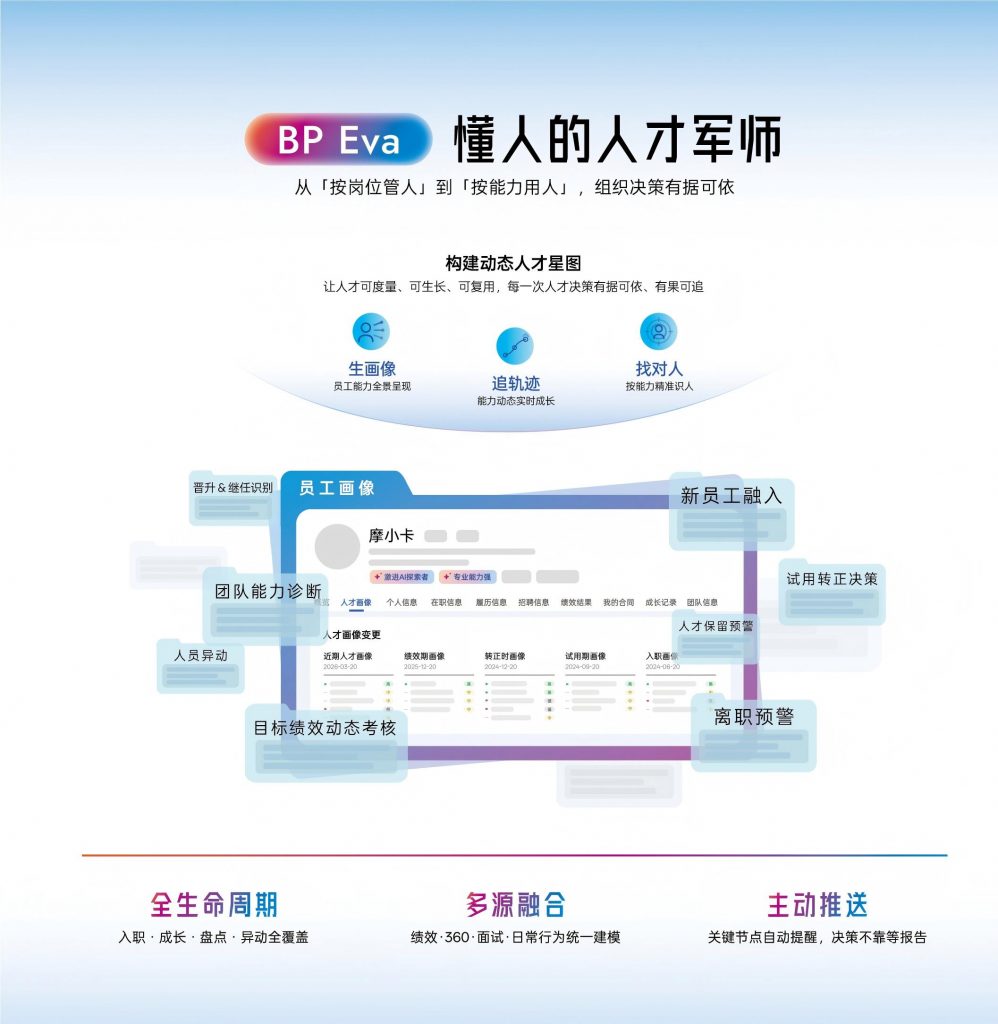
识别你的画像是否已经失真
如果你是 HR 负责人,有几个信号值得警惕:
招聘漏斗的某个环节转化率持续异常低,但候选人数量并不少——这通常意味着筛选标准有问题,而不是人才市场的问题。
业务方频繁在面试环节推翻系统评分,或者经常说感觉不对但说不出哪里不对——这往往是画像与实际决策标准已经脱节的信号。
新入职员工在试用期的表现方差很大,有人迅速成为骨干,有人迟迟无法上手,而两者在招聘阶段的评分差异并不显著——这说明画像捕捉到的维度与岗位成功所需的维度存在偏差。
一个快速自检方式:把过去一年表现最好的 5 名员工和表现最差的 5 名员工的背景拿出来对比,看两组人的共同特征是否与你现有的人才画像吻合。如果吻合度低于 60%,画像基本可以确认需要重建。
最后的启示:用人标准本身也需要被管理
徐总在 2025 年年底的内部复盘会上说了一句话,后来在公司里广为流传:我们管理了流程,管理了数据,但没有管理标准本身。
这句话说到了问题的核心。招聘流程的数字化程度可以很高,候选人跟踪可以做到精细,面试记录可以自动生成——但如果用人标准本身是静态的、失真的,这一切的效率提升,不过是在更快地做错误的筛选。
人才画像不是一次性的项目交付物,而是一个需要持续运营的动态资产。它需要被定期审视,需要用实际入职数据来校验,需要随着业务演变而演变。在这件事上,那些真正做得好的企业,往往不是因为一开始的画像有多精准,而是因为他们建立了一套让画像持续进化的机制。
这个机制,在 2026 年已经可以由 AI 来承担。
你们的人才画像,上次更新是什么时候?
Moka AI 为企业 HR 团队提供 AI 原生的招聘同事系统,招聘 Eva 通过持续学习企业真实的录用决策和入职表现数据,构建动态更新的人才画像模型,帮助企业把识人能力从少数人的经验变成组织可积累的资产。如果你正面临招聘转化率低、人才质量不稳定的困境,不妨用数据来验证问题根源在哪里。