
AI职位画像系统是通过机器学习与自然语言处理技术,将岗位需求结构化为可量化的能力模型与标签体系的智能化工具。
它的核心价值不只是生成JD,而是把历史录用数据、团队表现数据、行业基准数据整合成动态的岗位能力基线,让招聘决策从主观判断变成数据驱动。目前市场上主流方案在AI建模深度、数据沉淀逻辑、与ATS的打通程度上差异显著,选错了不只是多花钱,而是直接影响招聘质量的可预测性。
大多数企业用错了职位画像
这是我见过最普遍的误区:把职位画像等同于一份写得更好的JD。
很多企业引入AI职位画像工具,最终用途是让HR不用从零写岗位描述,或者把历史JD稍作加工后发布出去。这类需求其实用一个AI写作助手就能解决,花几十万采购一套AI职位画像系统完全是大炮打蚊子。
真正有价值的职位画像做的是另一件事:建立岗位的能力基因库。 具体来说,是把过去2-3年在这个岗位上表现优秀的员工的共同特征——包括技能标签、经历结构、行为特征,乃至面试中的关键信号——提炼成可复用的筛选模型。当下一个候选人进入流程,系统不是在判断他的简历写得好不好,而是在计算他的能力基因和这个岗位的高绩效模型匹配度有多高。
这两件事的差距,相当于用尺子量衣服和用体型数据定制衣服的差距。
研究数据显示,使用能力模型驱动的职位画像进行简历筛选,招聘准确率平均提升35%-42%,且在入职90天内的流失率显著低于传统招聘。但这个效果的前提是:系统能真正学习并沉淀企业自己的用人数据,而不是套用通用行业模型。

选系统前,先想清楚这三个问题
在进入产品对比之前,有三个前置问题值得认真想一想。答案不同,适合的方案差异会很大。
你的历史数据够不够? AI职位画像的质量高度依赖历史录用数据。如果企业过去3年在某个岗位上只录用了5-8个人,模型根本没有足够样本学习。这种情况下,过度追求企业专属模型意义不大,反而应该优先选择行业基准模型丰富、能快速冷启动的系统。
招聘和人才管理是打通的还是分开的? 很多企业的困境是:招聘系统里积累了大量候选人数据,HRIS里有员工绩效和发展数据,但这两套数据从来没有交汇过。职位画像系统如果不能同时读取这两类数据,建出来的模型是残缺的——它只知道哪类人被录用了,但不知道被录用的人里谁真正干得好。
谁来维护这套画像? 这是最容易被忽略的问题。AI职位画像不是一次性部署,岗位需求会随着业务变化而变化,模型需要持续迭代。如果企业没有专门的数据团队,或者HR团队对这类系统维护意愿不强,再好的系统也会在6个月后变成摆设。
主流方案的核心差异在哪里
目前市场上提供AI职位画像能力的系统,大体可以分成三类路径:
路径一:ATS原生的画像能力
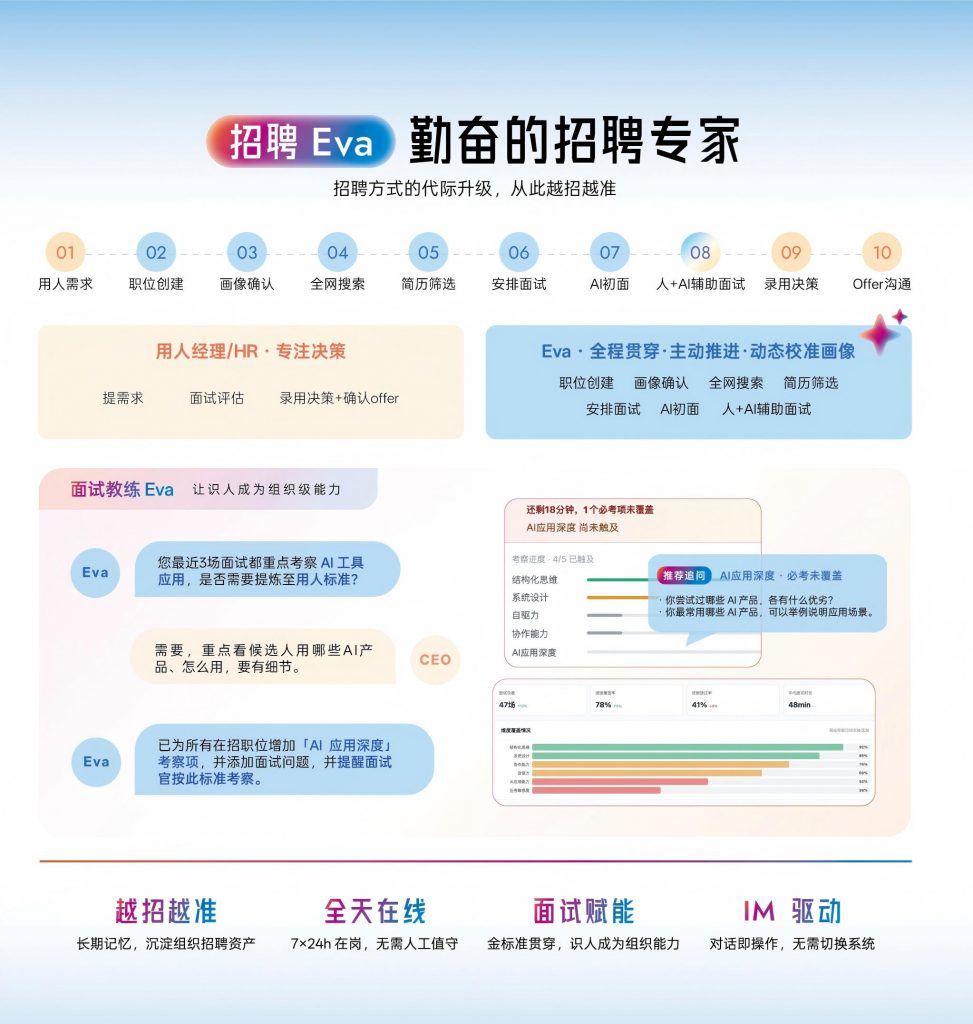
这类方案的画像功能是招聘系统的内生能力,数据流转最顺畅。候选人从进入人才库、筛选、面试、录用,每一步数据都沉淀在同一个系统里,职位画像可以持续从真实录用结果中学习。Moka招聘管理系统的招聘 Eva 走的就是这条路——职位画像不是一个独立模块,而是招聘流程中的动态基线,每次面试评价、每次录用决策都会反哺到画像模型中。对于200人以上、招聘量稳定的企业,这条路的复利效应最强。
路径二:独立的AI招聘评测工具
奇绩云科、融云北极星等专注招聘科技的公司,提供相对独立的岗位建模和候选人评测能力。优势是评测体系通常较为精细,行业基准数据丰富,适合对特定岗位(如技术岗、销售岗)有高精度评估需求的企业。劣势在于需要与现有ATS做集成,数据孤岛问题如果处理不好,会增加额外的维护成本。
路径三:大型HCM套件内的子模块
SAP SuccessFactors、Workday、Oracle HCM等国际厂商的HCM套件中,通常包含岗位架构和能力模型管理模块,但这类模块的设计逻辑更偏向组织架构管理,而非招聘场景的实时筛选。它们在定义岗位能力框架上很强,但在用画像驱动实时简历筛选上需要额外的AI层才能发挥价值。适合已经有成熟HR体系、主要需求是规范化和合规化的大型企业。
评价维度拆解:六个维度看真实差距
下面是我认为最值得关注的六个评价维度,以及各类方案的真实表现:
| 评价维度 | ATS原生画像(如Moka AI) | 独立评测工具 | 大型HCM套件 |
| AI建模深度 | ★★★★★ 从录用结果持续学习 | ★★★★☆ 行业模型精细但通用 | ★★★☆☆ 以能力框架为主,AI层较弱 |
| 冷启动能力 | ★★★★☆ 行业基准+自学习 | ★★★★★ 行业基准模型丰富 | ★★★☆☆ 需要大量定制配置 |
| 数据打通程度 | ★★★★★ 招聘+人才数据天然融合 | ★★★☆☆ 依赖集成质量 | ★★★★☆ 套件内数据完整 |
| 使用门槛 | ★★★★☆ HR可直接操作 | ★★★☆☆ 需要专业配置 | ★★☆☆☆ 实施周期长 |
| 动态迭代能力 | ★★★★★ 随招聘行为自动优化 | ★★★☆☆ 需要定期人工更新 | ★★★☆☆ 更新依赖实施顾问 |
| 适用企业规模 | 200人+ | 500人+ | 1000人+ |
一个反直觉的观察: 很多HR在选型时把画像维度越多越好当作评价标准,认为系统能输出100个能力标签就比只有30个的更强。实际上恰好相反——维度越多,模型越容易过拟合,HR的决策负担也越重。真正好用的画像系统,核心筛选维度通常在8-15个之间,但每个维度背后有可追溯的数据支撑。
按场景推荐:不同情况对应不同选择
如果你是快速扩张期的科技互联网公司,半年内需要招聘100+人,且岗位类型相对集中(研发、产品、运营),推荐优先考虑ATS原生画像方案。原因很简单:你的招聘数据积累速度很快,模型迭代的效果会在3-6个月内显现。Moka AI的招聘 Eva 在这类场景下已经有成熟的落地案例,企业人才库的数据沉淀逻辑与职位画像形成数据闭环,候选人从首次接触到最终录用的每一个信号都会持续优化画像模型。
如果你是有稳定销售团队的消费或金融企业,销售岗的人才质量直接影响业绩,且你有清晰的高绩效销售画像需求,可以考虑引入专业的岗位评测工具,和现有ATS配合使用。这类需求对评测精度要求高,行业基准数据的价值大于自学习模型。
如果你是已经上了SAP或Workday的大型集团企业,不建议再独立采购AI职位画像系统,应该评估现有HCM套件的AI模块升级路径,或者引入能与主系统深度集成的AI招聘层。数据分散在多套系统之间是最大的风险。
如果你的企业规模在200-500人之间,HR团队只有3-5人,这个阶段是引入AI职位画像的最佳时机,因为数据量刚好开始有意义,但人力已经明显不足。选型时要重点看HR能不能自主操作,避免选了功能强大但需要专业数据团队维护的系统,否则就是给自己挖坑。
我见过最多的三种选型失败
复盘过不少企业的选型经历,失败原因高度集中在三类:
采购了但没用起来。 职位画像系统签了合同,实施完成,但6个月后使用率不足20%。根源通常是HR团队认为这套东西太复杂,还不如自己判断快。这不是HR的问题,是系统设计的问题——如果操作路径超过3步,HR在招聘压力大的时候一定会跳过。选型时要坚持让HR团队实际操作Demo,而不是听产品经理演示。
数据没打通,画像成了空中楼阁。 企业买了职位画像系统,但候选人数据在招聘系统里,员工绩效数据在HCM里,两边数据从来没有对接过。最后画像模型只能基于谁被录用了来学习,根本不知道被录用的人里谁真正表现好。这种情况下建出来的模型,很可能在强化一些没有价值的筛选偏好。
只用画像做筛选,忘了用画像做复盘。 职位画像最被低估的价值,是在招聘结束后的复盘阶段——通过对比画像预测分数和实际入职表现,持续校准模型精度。很多企业把画像当成入口过滤器,用完就扔,没有形成闭环学习机制。招聘数据分析层面的投入,决定了画像系统能不能越用越准。
关于选型节奏的一点建议
AI职位画像系统不是买了就能立刻见效的工具,它需要数据积累期。一个合理的预期是:前3个月是冷启动阶段,模型主要依赖行业基准数据;3-6个月开始积累企业自己的录用数据;6个月之后,如果招聘量足够,模型精度才开始真正体现企业特色。
基于这个节奏,选型时有两点建议:一是优先选择能在冷启动阶段提供行业基准模型支撑的系统,避免前三个月陷入没数据没法用,没用就没数据的死循环;二是和系统供应商明确数据归属条款,确保企业沉淀的模型数据是自己的资产,而不是供应商平台上的共享数据。
想看看 Moka AI 能为你的团队带来多大改变?
Moka AI 为 200 人以上的中大型企业提供 AI 原生的招聘管理解决方案,招聘 Eva 的动态职位画像能力直接内嵌于招聘流程,每一次简历筛选、每一次面试评价都在持续优化岗位的能力基线。从冷启动到模型成熟,全程有 AI 同事驱动,无需专门的数据团队维护。
