
用人标准学习系统是一种通过数据沉淀和机器学习,将企业隐性用人偏好转化为可复用、可进化的智能标准体系的技术系统。
它不是一份静态的岗位说明书,而是一个能从每次招聘决策中持续学习、动态迭代的组织能力基础设施。2026年,随着AI同事系统的成熟,用人标准学习系统正在从锦上添花变为组织刚需。
大多数人以为用人标准的问题是没有标准,但实际上是标准太多
用人标准学习系统的核心矛盾不在于企业缺乏标准,而在于每个面试官脑中都有一套隐性标准,彼此矛盾且无法对齐。
据行业数据显示,一家300人以上的企业,平均有12-15位不同层级的管理者参与面试决策。每个人对优秀候选人的定义都不同——技术总监看重架构思维,业务负责人在意沟通能力,HR关注文化匹配度。这些标准从未被系统化记录,更别提相互校准。
结果是什么?面试官越多,招聘质量的方差越大。 一家500人规模的互联网公司曾做过内部复盘:同一个岗位、同一批候选人,不同面试官的通过率差异高达40%。这不是候选人质量波动,而是评估标准在打架。
传统做法是写更详细的JD、做更长的面试官培训、搞更复杂的评分卡。但这些静态方案有一个致命问题:它们无法从结果中学习。 一个入职后绩效排名前10%的员工,当初面试时被看重的到底是哪些特质?一个试用期未通过的人,筛选环节漏掉了什么信号?没有反馈回路,标准永远停留在经验直觉层面。
用人标准学习系统解决的正是这个问题:它把散落在面试评价、绩效数据、离职分析中的信号,汇聚成一张动态进化的组织识人地图。

用人标准学习系统的三层架构:从数据采集到标准生成
一个完整的用人标准学习系统由数据层、分析层和应用层三部分构成,三者形成闭环而非单向流水线。
数据层:把拍脑袋变成有据可查
系统需要采集的不只是简历字段,而是整个招聘-入职-发展周期中的行为数据。包括面试官的评语文本、打分分布、决策时长,也包括入职后的绩效评级、项目表现、360度反馈。一家生命科学企业接入系统后发现,他们过去3年录用的研发人员中,面试时发表过SCI论文这个硬指标与入职后绩效的相关性只有0.12,而能清晰描述失败实验的原因这个软指标相关性高达0.67。这类洞察靠人力复盘几乎不可能获得。
分析层:机器学习识别什么特质真的管用
系统通过对比高绩效员工和低绩效员工在招聘阶段的差异特征,自动生成岗位的有效预测因子。这不是简单的统计频率,而是控制了岗位类型、团队风格、业务阶段等变量后的因果推断。比如,3年以上经验对销售岗位的绩效预测力可能远低于过去是否有从0到1开拓市场的经历。
应用层:让标准长在流程里
生成的标准不是一份PDF报告发给面试官看完就忘。它直接嵌入招聘流程管理的每个环节:简历筛选时自动匹配有效预测因子、面试问题库根据岗位标准动态推荐、面试评价表只呈现真正有区分度的维度。面试官不需要背诵标准,系统已经把标准变成了他操作流程的一部分。
你可能不知道的点:静态胜任力模型在2026年已经失效
大多数人以为定义好岗位胜任力模型就解决了用人标准问题。但2026年的人才市场已经让这个假设站不住脚。
原因有三:
岗位本身在快速变异。 AI工具的普及让很多岗位的核心能力要求每6-8个月就发生一次显著变化。2024年招一个内容运营,核心看文笔好、懂用户心理;2026年同一个岗位,能用AI工具高效产出内容并判断质量已经变成了新的核心能力。静态模型根本跟不上这个节奏。
团队组合比个人能力更重要。 研究显示,一个团队中如果已经有两个强执行型成员,再招一个同类型的人,边际贡献会急剧下降。用人标准不应该只看这个人行不行,还要看这个人加入后团队整体能力结构是否更优。这种动态组合逻辑,只有系统能实时计算。
候选人的能力迁移性被严重低估。 传统标准过度依赖行业经验和岗位匹配度,但越来越多的数据表明,跨行业候选人在创新型岗位上的绩效表现往往优于行业内跳槽者。用人标准学习系统能捕捉到这些反直觉的模式,帮助企业打破经验陷阱。
企业不用用人标准学习系统的真实代价
不是招聘慢一点那么简单。缺乏可学习的用人标准,企业付出的是三重隐性成本:
决策质量的不可复制。 公司里最会看人的往往是某一两个高管。他们的识人能力完全存在脑子里,一旦离职或精力有限无法参与所有面试,招聘质量立刻下滑。据统计,企业核心面试官离职后的6个月内,新员工试用期淘汰率平均上升23%。
重复踩坑的组织遗忘。 一个岗位招错人,复盘时大家会说下次注意。但没有系统记录,同样的错误6个月后大概率重演。一家800人的零售企业复盘发现,他们在区域经理岗位上连续三年犯同一个错误:过度看重过往管辖门店数量而忽略跨区域协调经验,导致新任区域经理在跨区域资源整合上频繁碰壁。
规模化扩张的天花板。 当企业从200人扩张到1000人,从每月招10个人变成每月招50个人,如果用人标准还停留在几个人的直觉层面,招聘质量必然稀释。扩张速度越快,稀释越严重。这也是为什么很多高速增长的公司在突破千人规模后,会出现一轮明显的人才质量塌方。
评估用人标准学习系统的四个关键维度
如果你的企业正在考虑引入或建设这类系统,以下四个维度决定了它能否真正发挥价值:
数据闭环能力(权重最高)。 系统能否打通从招聘到绩效的全链路数据?很多招聘管理系统只记录了面试通过/不通过,但无法关联入职后的表现数据。没有结果反馈,学习就无从谈起。评估时要重点看:简历数据、面试评价数据、offer决策数据、入职后绩效数据这四类数据源是否能在一个系统内完成闭环。
标准的动态迭代机制。 系统生成的标准是一次性输出还是持续进化?好的系统应该每季度甚至每月根据新的绩效数据自动修正预测因子的权重。去年有效的标准,今年未必适用。
与业务流程的嵌入深度。 标准生成后如何落地?如果只是输出一份报告,让面试官自行参考,落地率通常不超过30%。标准应该直接内嵌到简历筛选规则、面试问题推荐、评价表设计中,让面试官不知不觉就在使用经过验证的标准。
隐私合规与可解释性。 系统在分析员工绩效数据时,是否符合《个人信息保护法》的相关要求?生成的标准是否可解释、可审计?如果系统给出一个结论说这个岗位不应看重学历,它能否说明背后的数据逻辑?不可解释的黑箱标准在2026年的合规环境下风险极高。
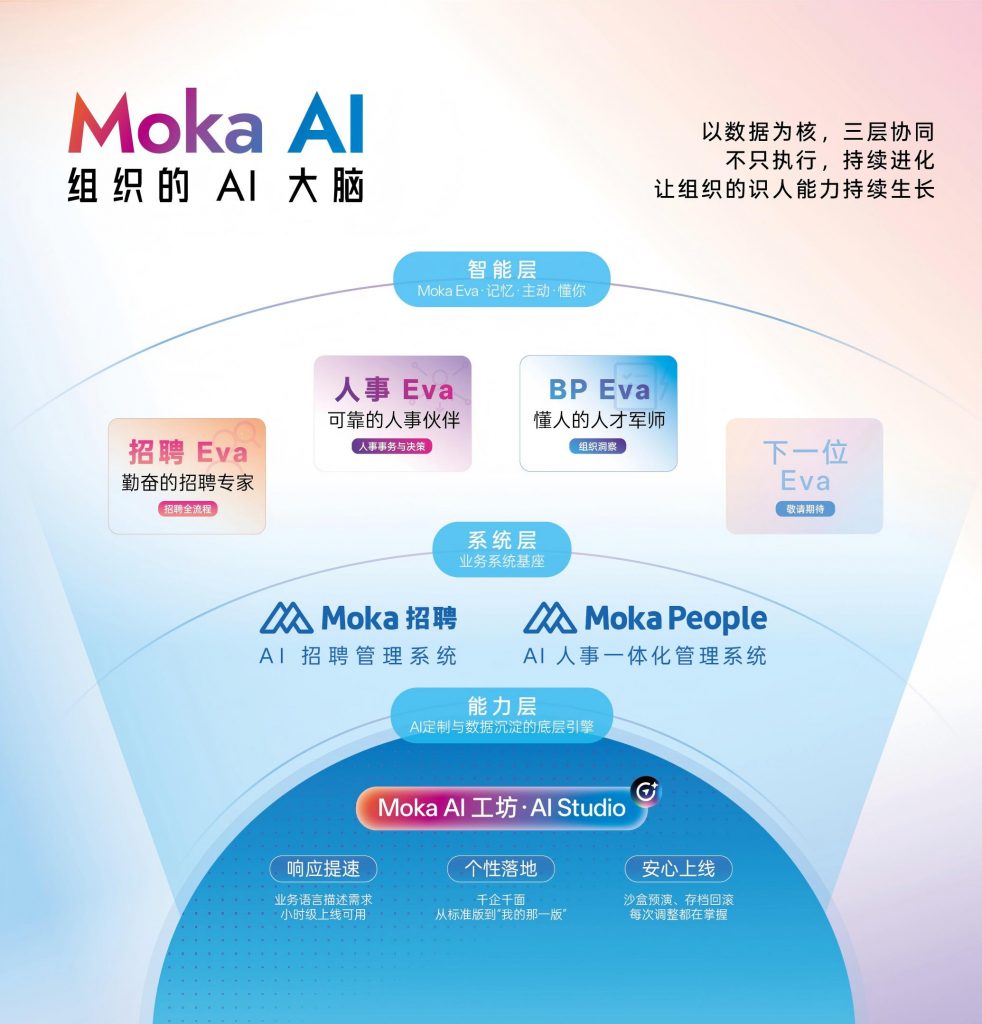
Moka AI 如何让用人标准从经验变成资产
在用人标准学习系统的落地实践中,Moka AI 的做法值得关注——它没有把这个能力做成一个独立模块,而是将其融入了AI同事系统的底层逻辑。
招聘 Eva 在每一次简历筛选和面试评估中,都在学习这家企业什么样的人最终表现好。当面试官在系统中写下评价、做出通过或淘汰的决策,这些数据不只是被记录,而是被持续分析。经过3-6个月的数据积累,系统能自动生成岗位维度的有效预测因子排序,并将其反哺到后续的简历推荐和面试建议中。
BP Eva 则从人才发展的视角补充了结果数据。员工入职后的绩效表现、能力成长轨迹、项目贡献度,这些信息通过企业人才库回流到招聘标准的校准循环中。一家金融服务企业在使用12个月后发现,系统自动修正了他们对风控岗位的关键能力判断:原来被高度看重的持有FRM证书预测力排名下降到第7位,而能用结构化方式描述复杂风险场景上升到了前3位。
Moka AI 工坊则让这套能力具备了千企千面的个性化潜力。企业可以用自然语言定义自己的业务逻辑,让系统在学习用人标准时考虑本企业独特的文化偏好、团队结构和业务阶段。
用人标准学习系统的终极价值,不是帮企业招到某一个好人,而是让识人能力从个人经验变成组织资产。 当一家企业积累了3年的招聘-绩效闭环数据,它对什么样的人适合我们的理解深度,会远超任何一个单独的面试官——而这种理解还在每天自动进化。
这就是为什么2026年的HR科技竞争焦点,已经从流程效率转向了组织智能。用人标准不再是写在纸上的几条要求,而是一个活的、会学习的系统能力。
想让你的组织识人能力从靠几个人的直觉升级为全员共享的智能标准?
Moka AI 为中大型企业提供 AI 原生的招聘与人才管理解决方案,覆盖从用人标准沉淀到招聘决策优化的全流程。立即免费试用,用数据验证效果。