
岗位画像自动生成,是指通过 AI 技术对企业历史招聘数据、在岗人员绩效表现、行业人才市场信息等多维度数据进行分析,自动输出包含岗位核心能力、经验要求、性格特质、薪酬范围等要素的标准化岗位画像。
’2026年,随着 AI Agent 在 HR 场景的深度应用,岗位画像已从人工拍脑袋走向数据驱动自动生成,平均将岗位需求确认时间从5天缩短至2小时内。

一个真实的招聘困局:岗位画像缺失的代价有多大
每到招聘季,最让 HR 崩溃的不是简历不够多,而是招的人不对。
一家800人规模的零售企业,HR 团队4人,去年扩招门店店长岗位30个。业务部门给的需求是要有经验、能抗压、会带人。HR 按照这个模糊描述发了 JD,收到1200份简历,筛了两周,推了60人面试,最终录用28人。半年后,其中9人离职,离职率超过32%。
这9个人的招聘成本、培训成本、业务空窗期损失加在一起,超过150万元。
问题出在哪?不是 HR 不努力,不是候选人不够多,而是从一开始,这个岗位到底需要什么样的人就没有被精确定义过。业务部门说的有经验是3年还是8年?能抗压是指应对客诉还是管理20人团队的压力?会带人是需要培训能力还是绩效管理能力?
这就是岗位画像缺失或模糊带来的系统性浪费。
为什么2026年岗位画像必须自动生成
传统的岗位画像构建方式已经跟不上组织变化的速度。
过去,一个岗位画像的产出流程大致是:HR 访谈业务负责人 → 参考行业通用 JD → 人工整理输出 → 反复确认修改。这个流程平均耗时3-5个工作日,且高度依赖 HR 的个人经验和业务理解深度。
2026年的企业面临三个新变量,让传统方式彻底失效:
组织架构调整加速。 据行业数据,中大型企业平均每年进行2.3次组织架构调整,新增岗位数量同比增长40%。很多岗位是全新的——比如AI 训练师私域运营负责人ESG 合规专员——没有历史模板可抄。
业务对人才的定义在持续演化。 同一个产品经理岗位,2024年和2026年需要的能力组合完全不同。如果还用两年前的画像去筛人,招来的人大概率跟不上业务节奏。
HR 团队的精力已经被稀释到极限。 一个 HR 平均同时跟进15-20个岗位的招聘,根本没有时间为每个岗位做深度调研和画像构建。结果就是复制粘贴上次的 JD成为常态。
AI 自动生成岗位画像,本质上是把少数资深 HR 的经验判断变成可规模化复制的组织能力。
岗位画像自动生成的工作原理:不是写 JD,是在构建人才标准
很多人把岗位画像等同于用 AI 写一份岗位描述,这是对这个概念最大的误解。
岗位画像自动生成,核心逻辑是从数据中提炼什么样的人能在这个岗位成功的规律,然后反向输出人才标准。它的数据来源至少包含四层:
历史招聘数据。 过去这个岗位录用了谁?面试通过率高的候选人有什么共同特征?入职后表现好的人和表现差的人,在简历阶段有什么可识别的差异?
在岗绩效数据。 当前团队中,高绩效员工的能力模型是什么?他们的教育背景、过往经历、性格特质有没有规律性聚类?
行业人才市场数据。 市场上这类人才的供给量如何?薪酬分位值是多少?竞争对手在用什么条件吸引同类人才?
岗位上下游协作数据。 这个岗位需要跟哪些部门协作?协作场景对沟通风格、专业深度有什么隐含要求?
AI 将这四层数据交叉分析后,输出的不是一篇漂亮的 JD 文案,而是一份结构化的人才画像——包含硬性条件(学历、年限、技能证书)、软性特质(沟通风格、抗压类型、学习速度)、薪酬建议区间、以及在这个岗位上最可能失败的人长什么样的反面画像。
这才是自动生成的价值所在:把模糊的感觉变成可衡量的标准。
如果不解决岗位画像问题,企业会持续承受三重损失
招聘效率的隐性消耗。 岗位画像模糊,直接导致简历筛选标准不统一。同一个岗位,张 HR 觉得候选人合适,李 HR 觉得不合适,业务面试官又有自己的偏好。据行业研究,画像不清晰的岗位平均招聘周期比画像清晰的岗位长12个工作日,每多一天空缺,业务损失以千元计。
人岗匹配的系统性偏差。 没有数据支撑的画像,本质上是面试官的直觉匹配。而人的直觉存在大量认知偏差——倾向于招和自己相似的人、被表达能力强的候选人吸引、忽略岗位真正需要的底层能力。这种偏差在单次招聘中可能不明显,但放到全年50-100个岗位的规模上,就是巨大的人才资产损耗。
组织知识的持续流失。 一个资深 HRBP 离职,他脑子里对各个岗位的理解、对业务团队偏好的把握,全部随之消失。下一个人来了又要从头摸索。岗位画像自动生成的底层价值之一,就是把这些个人经验沉淀为组织资产。
落地岗位画像自动生成的关键路径
实现这个能力不是买一个工具就够的,需要三个层面的准备:
数据基础层:让系统有记忆。 岗位画像的质量取决于数据的厚度。如果企业的招聘流程管理还停留在 Excel 阶段,候选人信息散落在邮箱和微信里,AI 就没有原材料可分析。打通从简历投递、面试评价、录用决策到入职后绩效表现的完整数据链路,是前提条件。
模型能力层:从通用大模型到 HR 专业模型。 通用 AI 写 JD 可以,但构建岗位画像需要对 HR 专业场景的深度理解——什么是胜任力模型、怎么识别文化匹配度、如何判断一个5年经验要求是否合理。这需要在 HR 垂直数据上训练过的专业模型。
业务协同层:AI 输出 + 人类校验的闭环。 自动生成不等于完全不需要人参与。最佳实践是 AI 输出画像初稿,HR 和业务负责人在此基础上做校验和微调,然后把调整结果反馈给系统,形成持续优化的飞轮。
一个大多数人忽略的问题:岗位画像不是静态文档
很多企业即使做了岗位画像,也是做完就存档,三年不更新。但人才市场在变、业务需求在变、团队结构在变——一份静态画像的有效期可能只有6个月。
真正有价值的岗位画像自动生成系统,必须具备动态更新能力:当新的招聘数据产生、当绩效评估完成、当行业薪酬发生变化时,画像应该自动刷新,并提醒 HR这个岗位的人才标准可能需要调整了。
这也是为什么岗位画像自动生成不能是一个独立的小工具,它必须嵌入招聘管理系统的完整数据闭环中才能真正发挥价值。
Moka AI 的实践:用 AI 同事把岗位画像从经验活变成系统活
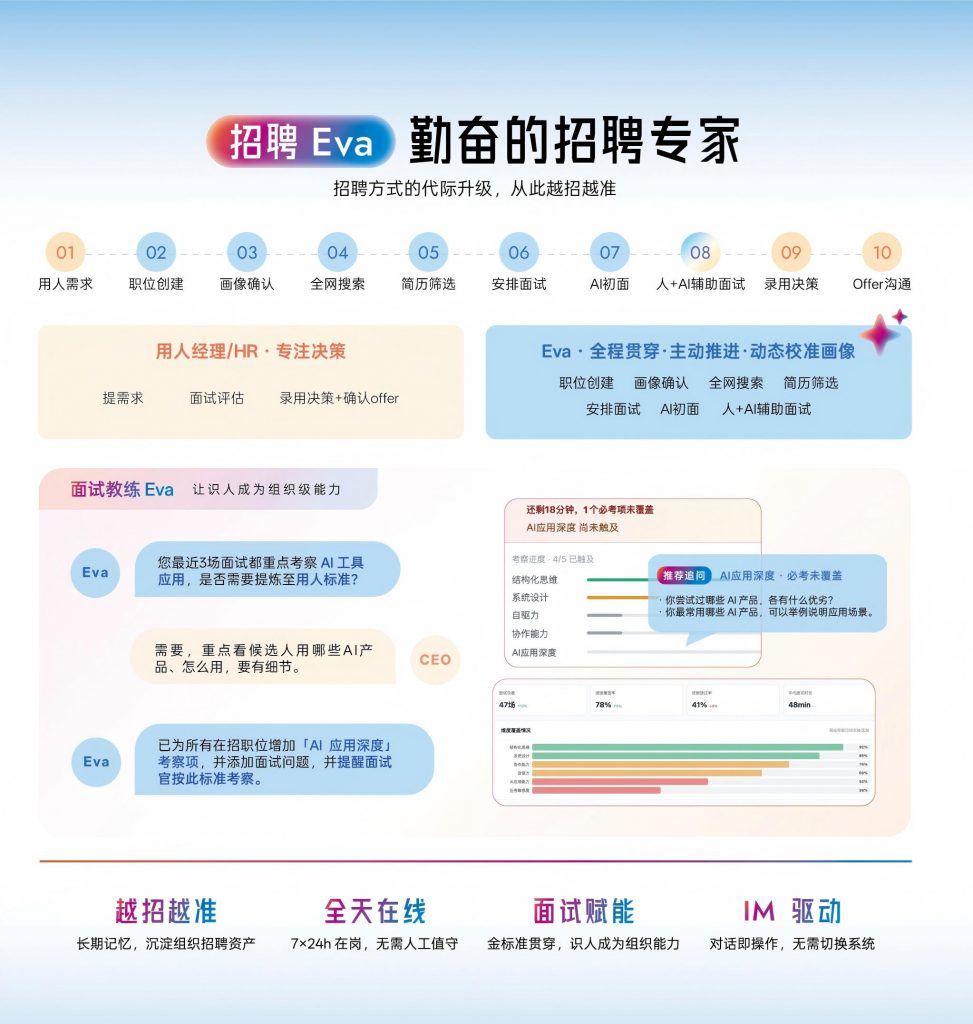
在岗位画像自动生成这个场景中,Moka AI 的招聘 Eva 提供了一个值得参考的落地路径。
招聘 Eva 作为企业的 AI 招聘同事,能够基于企业在 Moka 招聘系统中积累的历史招聘数据、面试评价记录、人才库信息,结合岗位的组织架构位置和协作关系,自动生成多维度的岗位画像。
区别于市面上用大模型写 JD的方案,招聘 Eva 的画像生成有三个特点:
基于企业自身数据,而非通用模板。 同样是高级产品经理,一家 SaaS 公司和一家消费品公司需要的人完全不同。招聘 Eva 会从企业自己的成功招聘案例中提炼规律,生成的画像天然贴合企业实际。
画像与招聘流程打通。 生成的画像不是一份静态文档,而是直接关联到简历筛选标准、面试评估维度和人才推荐逻辑。画像更新了,整个招聘漏斗的筛选逻辑跟着自动调整。
越用越准的数据飞轮。 每一次招聘完成后,录用人员的后续绩效表现会反哺画像模型——这次按这个画像招的人,表现到底好不好?系统持续修正对好人才的定义。
一家300人的生命科学企业在使用这个能力后,岗位需求确认环节从平均4天缩短到半天内,用人部门和 HR 之间因为招什么样的人产生分歧的情况减少了70%。

评估岗位画像自动生成方案的五个维度
如果你正在考虑引入这类能力,建议从以下角度评估:
| 评估维度 | 关键问题 | 理想状态 |
| 数据深度 | 能分析哪些数据源? | 覆盖招聘+绩效+市场三层数据 |
| 输出质量 | 画像是否包含反面画像? | 正反两面,含量化指标 |
| 系统集成 | 画像能否直接驱动筛选逻辑? | 与 ATS 流程深度打通 |
| 动态更新 | 画像多久刷新一次? | 基于数据事件实时触发 |
| 可解释性 | AI 的画像依据能否回溯? | 每个维度可追溯数据来源 |
★★★★★ 数据深度和系统集成是最关键的两个维度——前者决定画像的准确性,后者决定画像能否真正产生业务价值而不是又多了一份没人看的文档。
想看看 AI 同事系统能为你的招聘团队带来多大改变?
Moka AI 为中大型企业 HR 团队提供 AI 原生的招聘解决方案,覆盖从岗位画像生成到人才精准匹配的全流程。立即免费试用,让每一次招聘决策都有数据支撑。
