
在全球化招聘日益普遍的当下,企业常会收到来自不同国家、不同语言的简历,手动解析这些简历不仅耗时耗力,还容易出现信息遗漏、归类混乱等问题。而 AI 增强的 OCR 技术,恰好为这一难题提供了高效解决方案。本文将围绕 “企业如何借助 AI 增强的 OCR 技术实现多语言简历自动解析与归类” 展开,从技术原理、核心价值、实施要点等方面进行拆解,帮助 HR 和企业管理者快速掌握相关方法,提升招聘流程效率,精准挖掘优质人才。
_09-2-1024x576.jpg)
01 核心认知:AI 增强的 OCR 技术与多语言简历处理的适配性
OCR 技术即光学字符识别技术,能够将图像中的文字转换为可编辑的文本信息,而 AI 增强的 OCR 技术在此基础上融合了人工智能算法,具备更强的文字识别精度和语境理解能力。
多语言简历的特点是语言种类繁杂、格式多样,部分简历还存在字体不统一、排版不规则等问题,传统 OCR 技术难以精准识别,而 AI 增强的 OCR 技术通过深度学习,可适配多种语言的字符特征,即使是复杂格式的简历,也能准确提取关键信息。
这种适配性让企业在处理多语言简历时,摆脱了语言壁垒和格式限制,为自动解析与归类奠定了基础。
02 核心价值:AI 增强 OCR 赋能多语言简历处理的实际意义
对于企业而言,借助 AI 增强的 OCR 技术处理多语言简历,核心价值体现在效率提升、精准度保障和成本控制三个方面。
在效率上,AI 增强的 OCR 技术可在短时间内完成大量多语言简历的解析,相比人工处理,速度提升数倍,让 HR 有更多时间聚焦人才沟通等核心工作;在精准度上,该技术能精准提取简历中的姓名、工作经历、技能特长等关键信息,减少人工录入的错误;在成本上,自动化处理模式降低了对专职简历处理人员的需求,间接减少了企业的人力成本。
同时,规范的简历解析与归类,也为企业人才库的建设提供了高质量的数据支撑。
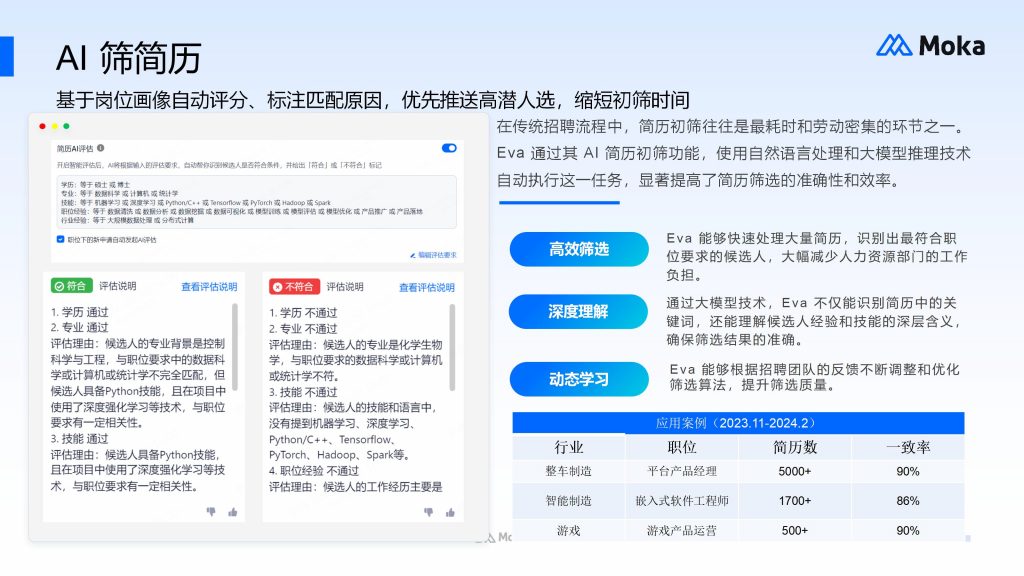
03 实施要点:企业落地 AI 增强 OCR 多语言简历处理的关键步骤
企业要成功借助 AI 增强的 OCR 技术实现多语言简历自动解析与归类,需遵循明确的实施步骤。
首先,要明确自身需求,比如企业常接收的语言类型、简历格式特点以及需要提取的核心信息字段,这是选择合适技术方案的前提;其次,选择适配的技术工具或系统,需重点关注工具的多语言识别覆盖范围、识别精度以及与现有招聘系统的兼容性;然后,进行规则配置,根据企业招聘需求,设定简历解析规则和归类标准,比如按岗位类别、语言能力、工作年限等维度进行归类;最后,做好后期优化,定期收集解析与归类过程中出现的问题,对技术模型进行迭代升级,提升处理效果。
04 工具适配:多语言简历处理的技术工具选择与应用要点
在工具选择上,企业需优先考虑功能全面、稳定性强的技术工具。优质的工具应具备多语言全覆盖、高识别精度、智能解析和灵活归类等核心功能,同时还能提供数据安全保障,避免简历信息泄露。
Moka 人力资源管理系统中融入的 AI 增强 OCR 技术,可支持多种主流语言的简历识别,能自动提取关键信息并按预设规则归类,且与招聘流程管理模块无缝衔接,实现简历处理与后续招聘环节的高效协同。
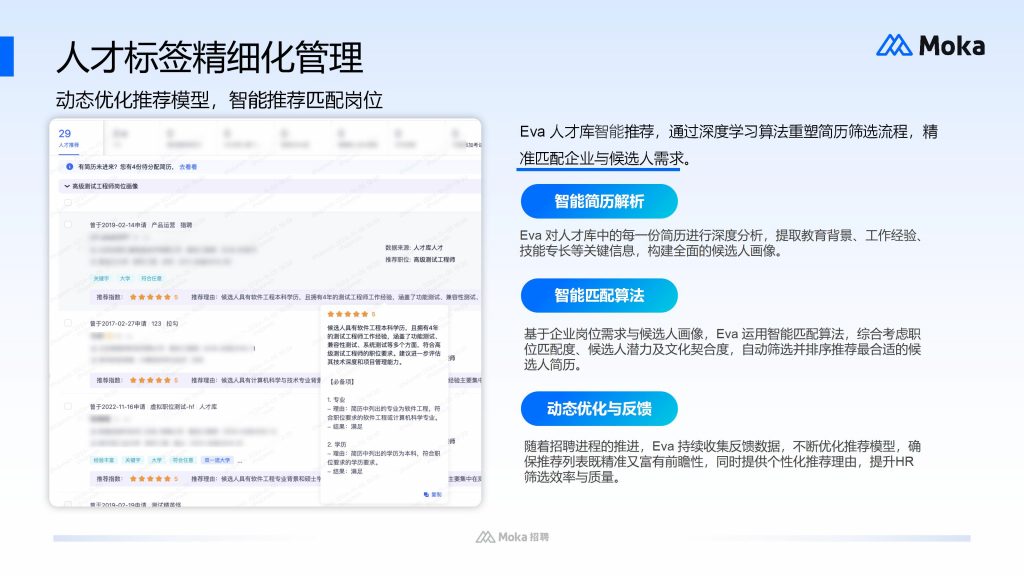
FAQ – 多语言简历解析中常见的问题及应对?
Q:不同语言的简历格式差异大,如何确保解析准确性?
A:选择支持自定义解析规则的工具,通过提前配置不同语言简历的格式模板,让 AI 增强的 OCR 技术按模板精准提取信息;同时,借助工具的深度学习能力,让系统在使用过程中不断适配各类格式,提升解析准确性。
Q:如何避免多语言简历中专业术语的识别错误?
A:优先选择内置多行业专业术语库的技术工具,同时企业可根据自身行业特点,向工具中导入专属术语库,让 AI 增强的 OCR 技术在识别过程中精准匹配专业术语,减少错误。
05 经验总结:企业应用 AI 增强 OCR 处理多语言简历的避坑指南
企业在应用 AI 增强 OCR 技术时,需避开一些常见误区。首先,切勿盲目追求技术的 “全能性”,而忽略自身实际需求,应根据常处理的语言类型和简历量选择合适的工具,避免资源浪费;其次,不要忽视数据安全,简历包含候选人敏感信息,需选择具备合规资质、数据加密功能完善的工具,防止信息泄露;最后,避免过度依赖技术,即使是 AI 增强的 OCR 技术,也可能出现少量识别误差,需安排专人进行定期抽检,确保简历信息的准确性。
Moka 在数据安全方面具备完善的保障机制,其 AI 增强 OCR 技术在实际应用中经过大量企业验证,稳定性和准确性更有保障,可帮助企业有效避开上述误区。
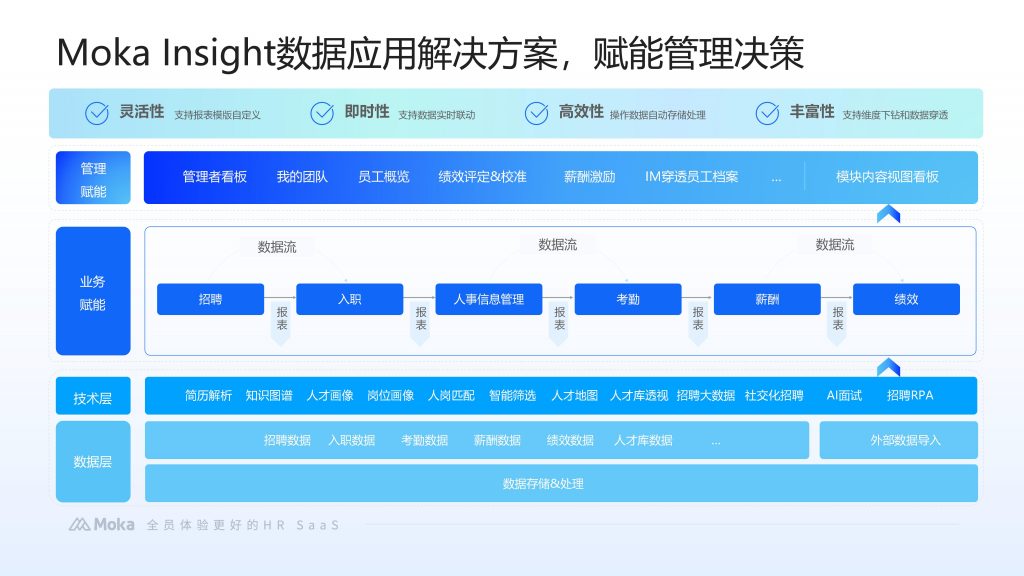
本文围绕 AI 增强的 OCR 技术在多语言简历自动解析与归类中的应用展开,核心是帮助企业解决全球化招聘中的简历处理难题。要点包括:明确 AI 增强 OCR 与多语言简历处理的适配性、认清技术带来的效率与成本优势、掌握实施步骤与工具选择要点、避开常见应用误区。
